If you have ever interacted with a basic customer support chatbot, you have likely experienced the frustration of “digital amnesia”; you explain a complex problem, the bot asks a follow-up question, and when you provide the specific answer, the bot has completely forgotten the original issue you were discussing just seconds ago.
So broken user experience happens because most entry-level chatbots treat every single message as a brand-new, isolated conversation. That’s why they lack the architectural foundation required to maintain context; therefore, they fail to providing genuine assistance.
For digital agencies, SaaS companies, and enterprise businesses, deploying a bot with digital amnesia is worse than having no bot at all. If you want to build a truly intelligent, context-aware chatbot Next.js and the Open AI API using modern frameworks.
You cannot simply plug a website directly into an AI model. You must engineer a custom system architecture: one that manually manages the AI’s memory.
This comprehensive guide breaks down the exact technical logic, data structures, and client-server architecture required to build a chatbot that remembers, reasons, and actually solves user problems.
1. The Core Obstacle: Understanding “Stateless” APIs
To understand the solution, you must first understand the fundamental problem: the Open AI API, like most modern web services, is completely “stateless.”
What “Stateless” Actually Means in Web Engineering
In software engineering, a “stateless” architecture means one specific thing:
That the server receiving a request retains absolutely no memory of any past requests. Every time a single piece of data is sent to the server, it is treated as an isolated, independent event. The server does not know who the user is; it does not know what the user asked three seconds ago; and it makes no attempt to connect the current message to previous interactions.
Open AI and other major artificial intelligence providers built their APIs this way intentionally. Stateless systems are incredibly fast and infinitely scalable. If Open AI had to store the active memory of millions of simultaneous conversations on their own servers, their infrastructure would collapse under the weight of the data. Forcing the API to be stateless, the burden of memory is pushed directly back onto the developer.
Why AI Models Do Not Remember You by Default
Because the API is stateless, “memory” is not a built-in feature of the artificial intelligence itself.
To illustrate:
If a user types, “My application keeps crashing on startup,” the AI will analyze that single sentence and suggest a generic fix. If the user’s next message is, “It only happens when I click the blue button,” the AI will be entirely confused; it will reply with something like, “What application are you referring to?”
Because the AI only sees the exact text transmitted in that specific millisecond, it has no historical context. Therefore, memory is a feature that must be meticulously built into the web application’s underlying data structure.
2. The Data Structure: Engineering the Conversation Array
To create the illusion of a continuous, intelligent memory, the web application must act as a perfect record-keeper. Instead of sending just the user’s newest message to the AI, the application must store the entire conversation in a dynamic list, structured programmatically as an “Array of Objects.“
The Anatomy of a Message Object
Within this array, we do not just store plain text. Every time a message is sent or received, a new object is created and pushed into the list; each object contains two mandatory pieces of data that give the AI context:
-
“The Role”: This defines who is speaking. It is typically labeled as “user” (the human typing on the website) or “assistant” (the artificial intelligence responding).
-
“The Content”: This is the actual string of text that was communicated (e.g., “My screen is cracked,” or, “Have you tried restarting the device?”).
Managing the Array Lifecycle
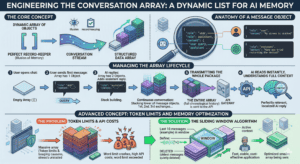
When the user opens the chat window, the array will be entirely empty. When they send their first message, the array holds one object; when the AI replies, the application captures that reply and pushes it into the array, which now holds two objects.
By the time a user has sent three messages and received three replies, the underlying data structure holds the entire chronological history of the conversation. When the user asks their fourth question, the application does not just send that fourth question: it takes the entire, massive array containing all previous questions and answers and transmits the whole package to the API.
The AI reads this history instantly, understands the full context of the problem, and generates a highly relevant, localized reply.
Advanced Concept: Token Limits and Memory Optimization
While sending the entire history solves the amnesia problem, it introduces a new engineering challenge: “Token Limits.”
AI models can only process a certain amount of text (tokens) at one time; furthermore, API providers charge developers based on how much text is sent. If a user chats with a bot for two hours, the conversation array will become massive. Sending a massive array back and forth every few seconds will result in exorbitant API costs and eventually crash the application when it hits the AI’s maximum word limit.
To solve this, senior developers implement a “Sliding Window” algorithm. Instead of sending the infinite history of the chat, the application is programmed to only send the last ten or fifteen messages. As new messages are added to the bottom of the array, the oldest messages at the top are quietly deleted. This ensures the bot remembers the immediate context of the conversation while keeping the application fast, stable, and cost-effective.
If you are interested here is the related content link. Ai Applications
3. The “System” Role: Programming the Brain and Boundaries
Before the user even types their first word, the application must establish the rules of engagement. This is done by injecting a hidden, permanent message at the very top (Index 0) of the conversation array; this is known as the “System Prompt.”
Defining the AI Persona
The system prompt is never visible to the user on the frontend, but it acts as the unbreakable psychological baseline for the AI. Because the AI reads the entire array from top to bottom every time a message is sent, the system prompt is the very first thing it processes.
A well-engineered system prompt defines exactly how the AI should behave.
For example: “You are an expert, highly technical support agent for a premium web development agency; you speak in a professional, concise, and helpful tone.” By establishing this persona at the system level, the AI will never break character, no matter what the user asks.
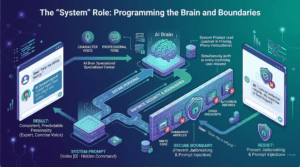
Setting Security and Behavior Boundaries
Beyond just giving the bot a personality, the system prompt is a critical security measure against “prompt injection” or “jailbreaking.”
Users will often try to trick customer support bots into writing code for them, generating inappropriate content, or offering discounts the company does not actually provide. The system prompt creates a strict boundary to prevent this.
A secure system prompt will include strict directives:
“You may only answer questions related to web development, hosting, and our specific agency services. If a user asks you to write code, summarize articles, or discuss politics, you must politely decline and steer the conversation back to technical support; under no circumstances are you allowed to offer financial discounts or authorize refunds.”
Because this rule sits at the foundation of the memory array, the AI will fiercely defend these boundaries throughout the entire conversation.
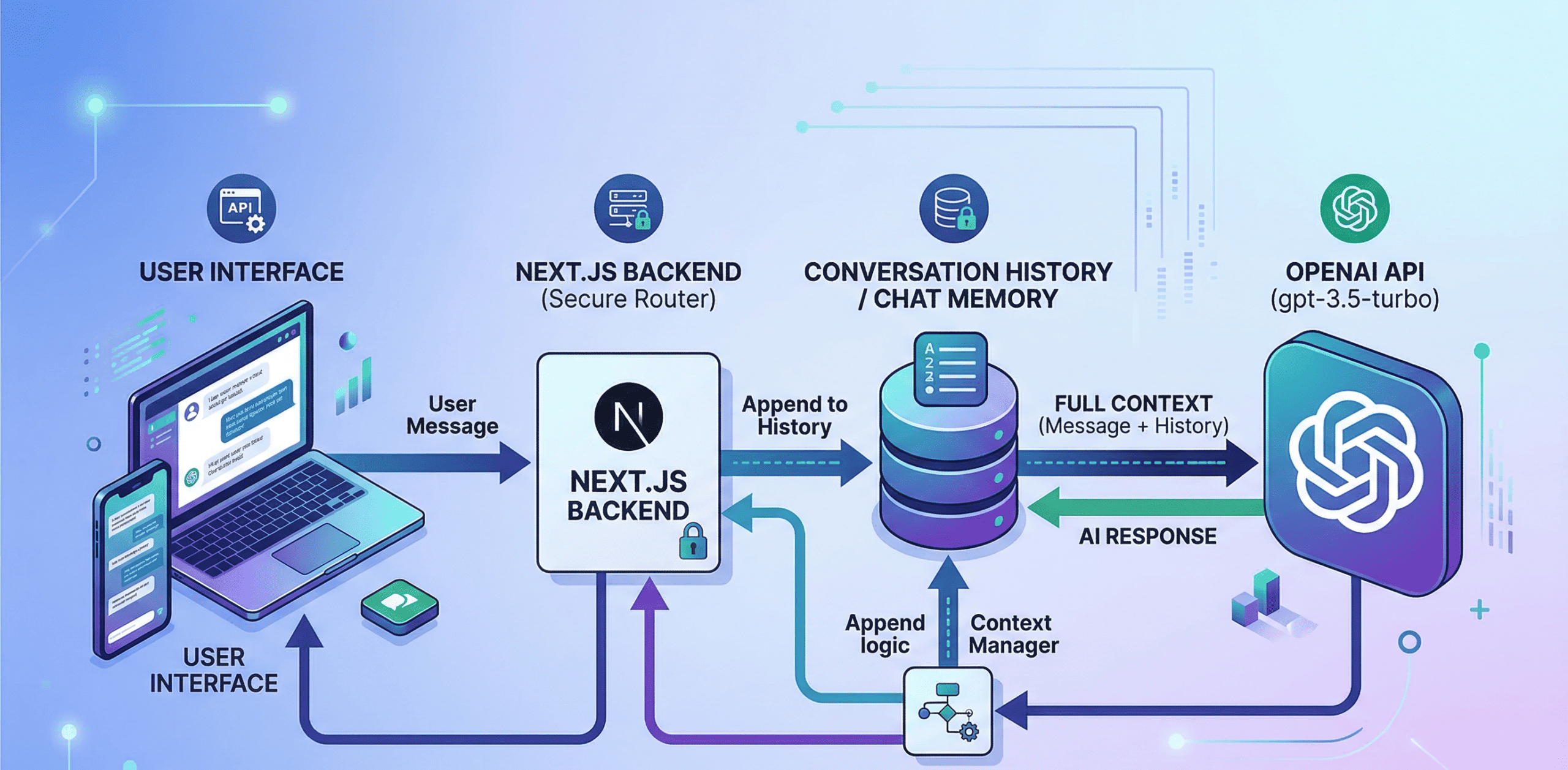
4. System Architecture: Separating Frontend from Backend
A professional, enterprise-grade AI integration is never built entirely on the frontend (the visual part of the website that the user sees and interacts with in their browser). It requires a highly secure Client-Server architecture; this is exactly why full-stack frameworks like Next.js have become the industry standard for AI development.
The Vulnerability of Client-Side API Calls
To communicate with Open AI, your application must use a private API key. This key is essentially a blank check tied directly to your company’s credit card.
If a developer builds the chatbot entirely in the frontend using standard HTML and JavaScript, that API key must be shipped to the user’s browser to make the connection work. This is a catastrophic security flaw: anyone visiting the website could simply right-click, open their browser’s developer tools, extract your secret API key, and use it to run their own massive AI applications entirely at your expense.
The Role of the Next.js Backend: Secure Server-Side Routing
To protect the business, the architecture must be split into two distinct environments:
-
The Frontend (Client-Side): This is the user interface; its only responsibility is to display the chat window, render the text bubbles, capture what the user types, and temporarily hold the conversation array in its local memory. It contains no passwords and no direct connection to the AI.
-
The Backend (Server-Side): This is the secure middleman. Built using Next.js API routes, this backend server sits safely out of reach of the public internet; it is the only part of the system that holds the secret Open AI API keys.
When the user hits “send,” the frontend transmits the conversation array to your own custom Next.js backend. The backend receives the array, silently attaches the secret API key behind closed doors, and then forwards the package to Open AI’s servers.
Once Open AI processes the data and sends back the answer, your backend relays that answer to the frontend. The user gets a seamless chat experience, and your API keys remain entirely invisible and secure.
5. The Complete Data Lifecycle: A Step-by-Step Breakdown
To fully grasp the elegance of this architecture, let us trace the exact, micro-second journey of a single piece of data through the entire system. When a user type, “How do I fix the server error?” and clicks the button to send it, the following sequence executes:
-
Data Capture: The frontend interface instantly captures the text string: “How do I fix the server error?”
-
Object Creation: The frontend wraps this text into a programmatic object, tagging it with the correct identity: {role: “user”, content: “How do I fix the server error?”}.
-
Array Appending: This new object is pushed to the very bottom of the existing conversation array, which will joining the system prompt and all previous messages.
-
Secure Transmission: The frontend packages this updated, comprehensive array and securely transmits it over the network to the Next.js backend API route.
-
Authentication and Forwarding: The Next.js backend receives the array, verifies the request, attaches the secure Open AI environment variables (API keys), and forwards the entire package to Open AI’s servers.
-
AI Processing: The Large Language Model processes the array; it reads the system instructions at the top, reads the historical context in the middle, and give formulates a precise, context-aware response based on the newest question at the bottom.
-
Data Return: Open AI transmits the generated response back to the Next.js backend server.
-
Frontend Rendering: The Next.js backend hands the text back to the frontend UI; the frontend wraps this new text into a new object ({role: “assistant”, content: “…”}), pushes it into the array, and dynamically renders the new chat bubble on the user’s screen.
If you having some issues visit this: Makeuser
Conclusion
Building a context-aware chatbot is fundamentally an exercise in data management and secure system architecture. By understanding that AI models are inherently stateless, developers can engineer robust, array-based memory systems that provide the AI with the exact historical context it needs to be genuinely helpful.
When combined with strict system prompts for behavioral boundaries, and secure server-side routing to protect API credentials, this architecture allows digital agencies to deploy highly intelligent, enterprise-grade support tools that solve real problems, elevate the user experience, and provide massive value to their clients.