If you have ever stared at a spinning loading wheel on a web application, you have likely witnessed a database architecture struggling to bridge the gap between human logic and machine reality.
In backend architecture, data does not exist in a single state. It lives a double life. On one side, it exists as a clean, organized Logical Storage layer the world of tables, relations, and business rules. On the other side, it exists as Physical Storage a chaotic, highly optimized realm of byte streams, disk sectors, and memory pages.
Understanding the separation between physical and logical data storage is not just an academic exercise. It is the key to building scalable applications, writing efficient queries, and saving thousands of dollars in cloud computing costs.
In this deep dive, we will explore the fundamental differences between these two layers, how they interact, and why mastering data independence is crucial for modern backend engineering.
What Are Developers Actually Searching For? (The Search Intent)
When users mostly backend developers, database administrators (DBAs), and system architects turn to the web to search for “logical vs. physical database architecture,” they are rarely looking for textbook definitions. Their searches are driven by specific, real-world problems.
")
Analyzing the search trends and related queries reveals three primary buckets of user intent:
1. The Performance Troubleshooting Intent
Common Web Searches: “Why is my SQL query so slow?”, “How to reduce disk I/O in PostgreSQL,” “Database indexing best practices.”
The Reality: Developers write a perfectly logical query that works in a local environment but times out in production. They turn to the web to understand why their logical command is causing a physical bottleneck. They are seeking to understand how data structures like B-Trees and memory buffers actually fetch their data.
2. The System Design & Scaling Intent
Common Web Searches: “How to scale a relational database,” “Database partitioning vs sharding,” “Choosing a database storage engine.”
The Reality: Architects building high-traffic applications realize that their logical schema (the tables and relationships) is solid, but their physical hardware is maxing out. They are researching how to physically distribute data across multiple servers without rewriting their entire application logic.
3. The Interview Preparation Intent
Common Web Searches: “What is physical data independence?”, “Three-schema architecture DBMS,” “Explain logical vs physical schema.”
The Reality: Computer science students and junior developers preparing for technical interviews need clear, concise explanations of these foundational concepts to prove their systemic understanding of database management systems (DBMS).
If you are intrested in more content like this Data Directories
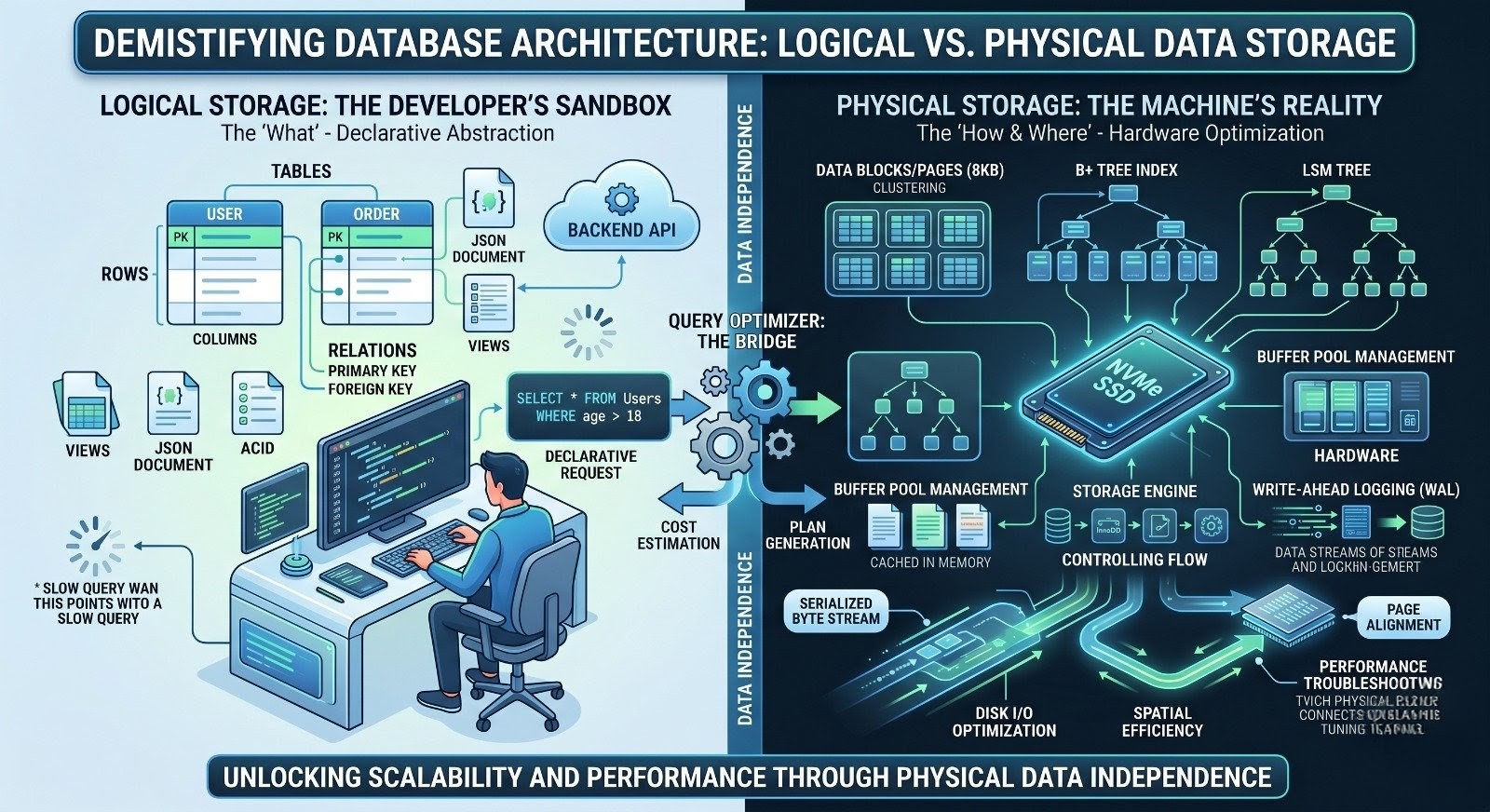
The Logical Storage Layer: The Developer’s Sandbox
Logical data storage is entirely conceptual. It is the “What” of database architecture. It represents how data is modeled, structured, and perceived by the application layer and the software engineers writing the code.

When you are mapping out a new application perhaps sketching out how user profiles relate to their order history you are working in the logical layer.
Core Characteristics of Logical Storage
-
Declarative Nature: You define what you want to happen, not how the machine should do it. When you write a SQL statement like
SELECT * FROM Users WHERE age > 18, you are making a logical request. -
Business Rules and Constraints: This layer enforces the rules of your business. Primary keys, foreign keys, unique constraints, and data types (like ensuring an email column actually contains an
@symbol) all live here. -
Normalization: The process of organizing data to reduce redundancy and improve data integrity. You break large tables down into smaller, related tables.
-
Data Structures: The logical layer speaks in terms of Tables, Rows, Columns, Views, JSON documents, or Graph nodes.
The Illusion of Simplicity
The logical layer is designed to be developer-friendly. It allows developers coding in Python, Node.js, or Java to interact with complex datasets using clean APIs and ORMs (Object-Relational Mappers) without ever needing to know the rotational speed of the server’s hard drive. It provides a clean, mathematical model of the application’s state.
The Physical Storage Layer: The Machine’s Reality
If the logical layer is the blueprint of a house, the physical layer represents the actual bricks, mortar, and plumbing. Physical data storage dictates exactly how that logical data is encoded, mapped, and permanently written to the underlying storage hardware (like an NVMe SSD).
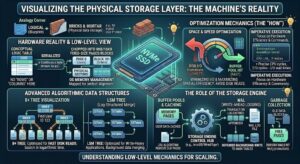
Core Characteristics of Physical Storage
-
Imperative Execution: This layer is about the how. It focuses on executing commands with maximum hardware efficiency.
-
Space and Speed Optimization: The primary goals here are minimizing disk I/O (Input/Output operations) and maximizing spatial efficiency. Disk reads are the slowest operation in a computer system, so the physical layer is built entirely around avoiding them.
-
Pages and Blocks: At this level, there are no “rows” or “columns.” Data is serialized and chopped into fixed-size chunks called Pages or Blocks (typically 8KB or 16KB). These sizes are chosen to align perfectly with the operating system’s memory management and the physical sectors of the hard disk.
-
Algorithmic Data Structures: To avoid scanning an entire hard drive to find one user record, the physical layer employs highly complex data structures. The most common is the B+ Tree, an advanced variation of a binary search tree optimized for disk reads. For write-heavy applications, engines might use Log-Structured Merge (LSM) Trees.
The Role of the Storage Engine
The physical layer is managed by the Database Storage Engine (e.g., InnoDB for MySQL, WiredTiger for MongoDB). The storage engine handles memory caching (Buffer Pools), write-ahead logging (WAL) for crash recovery, and garbage collection.
The Bridge: How Logical Becomes Physical
How does a clean, logical SELECT statement turn into a messy, physical disk read? The magic happens in a component called the Query Optimizer.
When a developer submits a query, the optimizer acts as a translator and a strategist.
-
Parsing: It breaks down the logical SQL syntax.
-
Cost Estimation: It looks at the physical statistics of the data (e.g., “How many rows are in this table?”, “Is there an index on this column?”).
-
Execution Plan Generation: It generates several possible physical paths to retrieve the data and selects the “cheapest” one in terms of CPU and I/O costs.
The optimizer decides whether to perform a Full Table Scan (reading every physical block) or an Index Seek (navigating the B-Tree directly to the required data).
Author will be here Makeuser
Why The Separation Matters: Physical Data Independence
The most critical concept binding these two layers is Physical Data Independence. This is the ability to change the physical storage structure without altering the logical schema or breaking the application code.
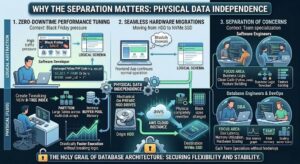
Why is this the holy grail of database architecture?
1. Zero-Downtime Performance Tuning
Imagine an e-commerce platform approaching Black Friday. The database is groaning under the weight of logical queries. Because of data independence, a Database Administrator can step in and alter the physical layer. They can create new B-Tree indexes, partition large tables across multiple physical disks, or increase the memory allocated to the buffer pool.
The application developers do not have to rewrite a single line of their Python or PHP code. The logical schema remains identical, but the physical execution becomes drastically faster.
2. Seamless Hardware Migrations
When a company moves its database from an on-premise server with magnetic HDD drives to an AWS cloud instance using high-speed NVMe SSDs, the physical storage layer is completely rewritten. Block sizes might change, and storage engines might be upgraded. However, because of the strict separation, the frontend web application interacting with the logical layer remains blissfully unaware of the migration.
3. Separation of Concerns
This architecture allows teams to specialize. Software engineers can focus on building features, writing clean code, and defining business logic. Database engineers and DevOps teams can focus on disk latency, memory utilization, and hardware scaling.
A Side-by-Side Summary
To encapsulate the differences, let’s look at how the two layers compare across key architectural metrics:
| Feature | Logical Storage | Physical Storage |
| Primary Audience | Software Developers, Application Logic | Database Engine, OS, Hardware |
| Core Objective | Data integrity, relationships, business rules | Speed, I/O efficiency, space optimization |
| Structural Elements | Tables, Views, Foreign Keys | Data blocks, B-Trees, Memory Pages, Pointers |
| Language/Interaction | SQL (Declarative), ORMs | Query Execution Plans (Imperative) |
| Impact of Modification | Changes require code updates (High Impact) | Changes improve/degrade speed (Zero Code Impact) |
Conclusion
The separation of logical and physical data storage is a masterclass in software abstraction. By hiding the brutal, mechanical reality of disks and memory management behind a clean, mathematical logical layer, modern databases allow developers to build incredibly complex applications with ease.
Yet, as any seasoned engineer will tell you, you can only ignore the physical layer for so long. When web traffic spikes and queries grind to a halt, it is the developers who understand the physical reality beneath their logical code who are able to scale their systems, optimize their performance, and keep the web running smoothly.